Asterisk’s dialplan treats every outbound call as a single attempt by default, so SIP trunk failover requires explicit configuration at three layers: dialplan routing that checks DIALSTATUS and retries on a secondary trunk, PJSIP endpoint monitoring via the qualify_frequency parameter, and DNS SRV records or multi-provider trunk registration for path-level redundancy across Philippine SIP providers.
Dialplan Routing Is Where Failover Logic Actually Executes
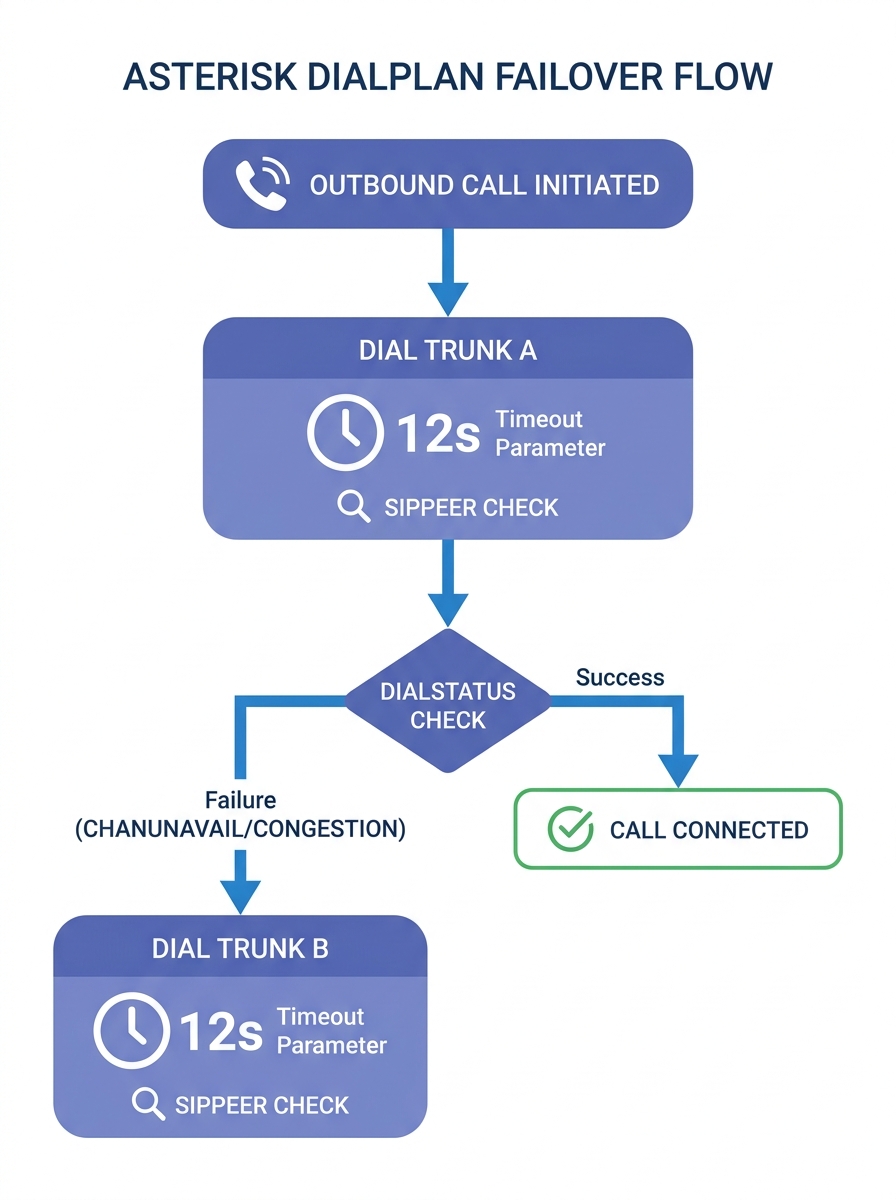
The failover decision in Asterisk happens inside the dialplan, specifically in the outbound routing context where the system decides which trunk carries each call. When a Dial() application sends a call to a SIP trunk and that trunk returns CHANUNAVAIL or CONGESTION, Asterisk doesn’t automatically try another path. It sets the DIALSTATUS channel variable and moves to the next priority in the dialplan. Your job is to write the logic that reads DIALSTATUS and reroutes the call to a backup trunk before the caller hears dead air.
The pattern documented across Asterisk community resources follows a consistent structure. The dialplan sends the call to Trunk A, checks whether DIALSTATUS equals CHANUNAVAIL or CONGESTION, and if true, sends the same call to Trunk B. A widely referenced thread on the Asterisk community forums walks through the basic sip.conf approach: register two separate SIP accounts on two different SIP servers, define each as a distinct peer in the SIP configuration, and build the dialplan to cascade through them. The SIPPEER() function can also check trunk status proactively, returning the registration state of a named peer so the dialplan can skip a known-dead trunk entirely rather than waiting for the Dial() attempt to time out. This proactive check reduces failover latency from the full Dial() timeout window (often 30 seconds by default) to under 1 second per skipped trunk.
For Philippine enterprises running Yeastar PBX systems, much of this dialplan logic is abstracted into the GUI’s outbound route configuration, where you assign a primary trunk and one or more failover trunks with drag-and-drop priority ordering. But if you’re running raw Asterisk 20 or 21, or FreePBX 17 with custom contexts, you’re writing this logic by hand. The critical detail most configurations miss is setting an appropriate dial timeout on the primary trunk’s Dial() application. Without it, Asterisk waits the full default 30-second timeout before moving to the failover trunk, which means the caller sits through half a minute of silence before their call even attempts the backup path. Setting a 10- to 15-second timeout on the primary Dial() forces faster failover without being so aggressive that you cut off legitimate ring time on slow-to-answer destinations. A BPO center in Makati handling 400 outbound calls per hour loses roughly 200 agent-minutes per day if every first-attempt failure burns 30 seconds instead of 12.
PJSIP Qualify and the Gap Between Reactive and Proactive Detection
Why does standard dialplan failover still impose a per-call penalty even when it’s correctly configured? Because it’s reactive. The system discovers a trunk is dead only when a real call fails against it, and then it retries on the backup. The first caller after a trunk failure absorbs the full timeout delay while Asterisk waits for the dead trunk to respond. For a hospital switchboard in Cebu routing 50 to 80 emergency pages per shift, or a hotel front desk in Boracay where a missed reservation call is a missed booking, that per-call delay during the detection window is operationally expensive.
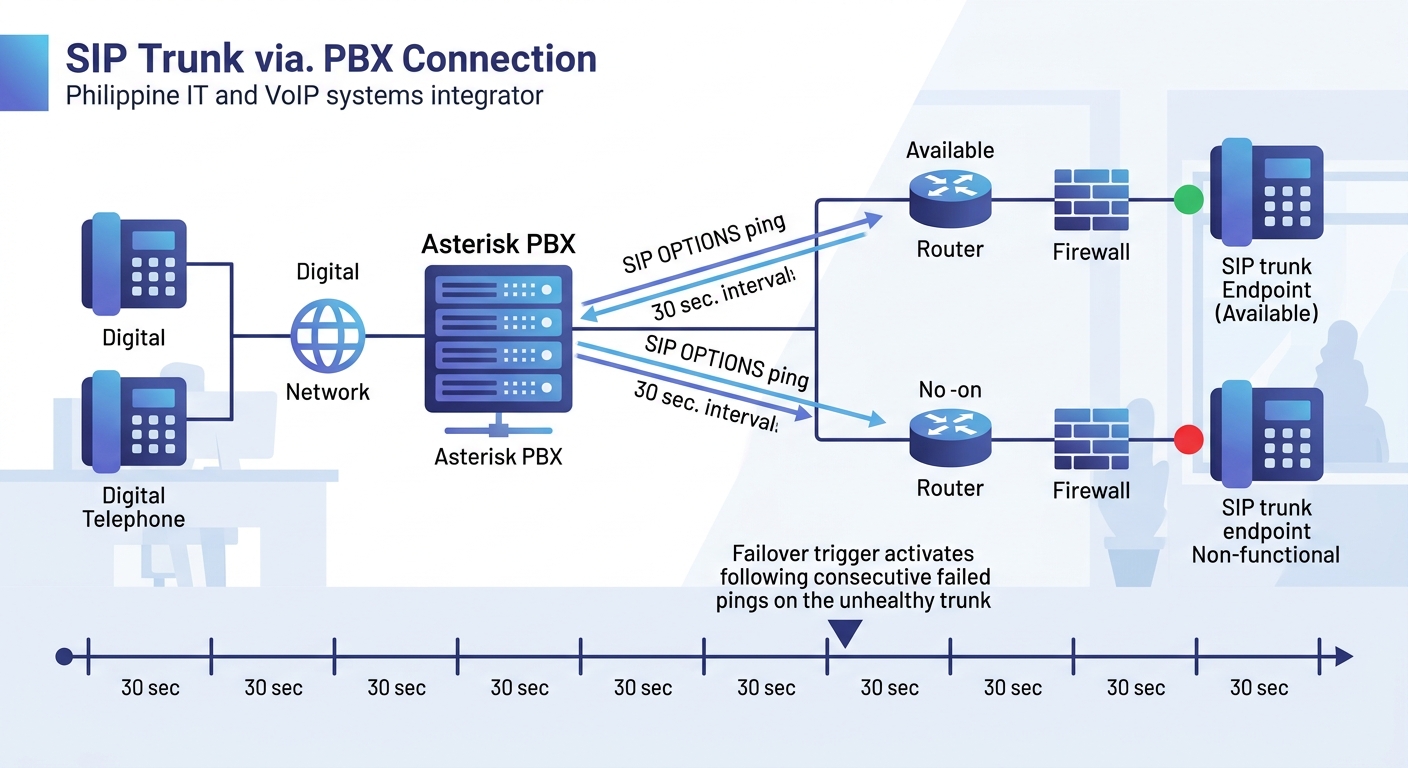
Proactive monitoring eliminates this penalty through SIP OPTIONS polling. In PJSIP (the modern channel driver that has replaced chan_sip in all current Asterisk releases since version 13), the qualify_frequency parameter tells Asterisk to send SIP OPTIONS ping messages to each trunk endpoint at a defined interval. Setting qualify_frequency to 30 means Asterisk pings the trunk every 30 seconds. If the trunk fails to respond within the qualify_timeout window (default 3.0 seconds), Asterisk marks that endpoint’s contact status as Unreachable. The dialplan can then check the endpoint’s contact status before attempting a call, skipping the dead trunk entirely and routing straight to the backup. Failover latency drops from your Dial() timeout (10-30 seconds) to effectively zero for every call after the first missed OPTIONS response.
The configuration lives in pjsip.conf under the aor (address of record) section for each trunk. You set qualify_frequency=30 and qualify_timeout=3.0, which means the system polls every 30 seconds and declares failure after 3 seconds of no response. The Asterisk CLI command “pjsip show endpoint” displays current contact status as Reachable, Unreachable, or Unknown, giving you a real-time view of trunk health. For environments that have already deployed monitoring tools to catch VoIP quality degradation, this OPTIONS-based health check adds a trunk-specific layer that complements your broader SNMP and RTP quality monitoring stack.
One caveat: some SIP trunk providers don’t respond to OPTIONS messages, or they respond inconsistently. The Smartvox knowledgebase observes that “most VoIP service providers will not be able to connect to your IP-PBX using a DNS host name,” and some providers treat unsolicited OPTIONS pings as suspicious traffic that gets rate-limited or dropped. Before relying on qualify_frequency for failover detection, verify with your Philippine SIP provider that their proxy responds to OPTIONS. Domestic carriers often require explicit provisioning to enable OPTIONS responses on their SIP trunking platforms. If you discover during testing that your provider silently drops OPTIONS, you’re back to reactive failover with DIALSTATUS checks, and your 30-second polling interval gives you nothing.
Philippine Provider Architecture and Multi-Trunk Path Diversity
Configuring SIP trunk redundancy on the Asterisk side solves half the problem. The other half is choosing and connecting to Philippine SIP providers in a way that gives you genuine path diversity. If both your primary and backup trunks terminate at the same provider’s single data center in Bonifacio Global City, and that facility loses its upstream fiber, your failover configuration routes calls from one dead path to another dead path at the same location.
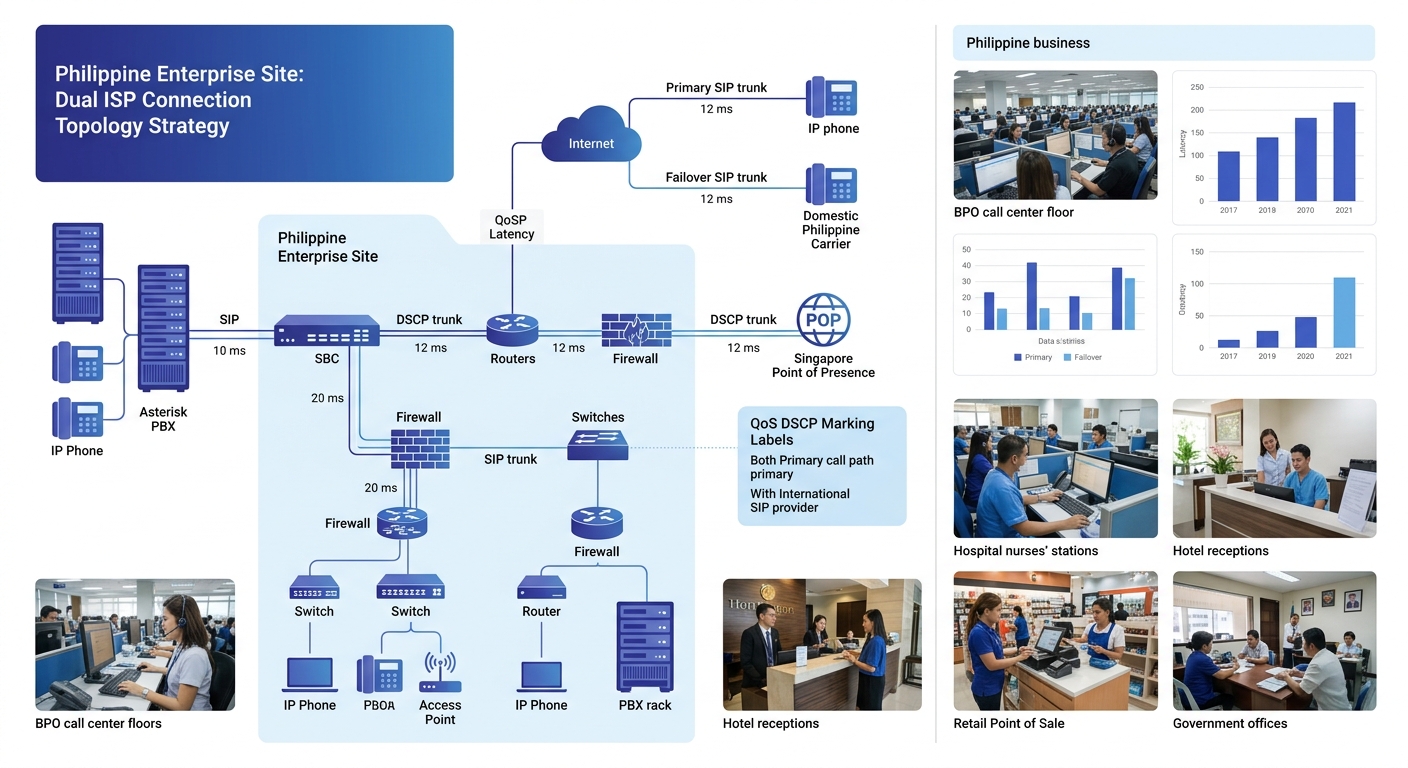
The Philippine SIP trunking market includes international providers with local DID numbers (Astraqom and AVOXI both offer Philippine SIP trunks compatible with Asterisk, FreePBX, and 3CX) alongside domestic carriers like PLDT and Globe that provide SIP interconnect bundled with their fiber circuits. A multi-provider design pairs one domestic trunk with one international trunk: the domestic trunk carries primary traffic with lower per-minute costs and tighter latency to local PSTN termination points (typically 15-25ms round-trip within Metro Manila), while the international trunk serves as the failover path with geographically separate infrastructure routed through Singapore or Hong Kong POPs at 40-80ms latency. This approach gives you provider-level diversity with infrastructure that shares no common failure points between the two paths.
DNS SRV records offer an additional failover mechanism at the protocol level. When you set srv_lookups=yes in your PJSIP endpoint configuration, Asterisk resolves the trunk’s domain name through DNS SRV records, which return prioritized and weighted lists of SIP proxy addresses per RFC 3263. If the highest-priority proxy (the one with the lowest SRV priority value, typically 10) is unreachable, Asterisk automatically tries the next record (priority 20) without any dialplan intervention. The IPComms failover guide describes this as standards-based failover because it relies on DNS resolution rather than custom dialplan logic. The limitation is that many providers don’t publish SRV records for their SIP proxy domains, making this approach entirely provider-dependent.
If both your primary and backup trunks terminate at the same provider’s single data center, your failover configuration routes calls from one dead path to another dead path at the same location.
The underlying network path matters as much as the SIP configuration itself. Philippine enterprises connecting Asterisk to SIP trunks over a single ISP circuit have an obvious single point of failure below the application layer. Dual ISP connections with SD-WAN or policy-based routing address this gap but introduce a NAT complication: when the active ISP path changes during failover, the PBX’s external IP address changes with it. Asterisk’s externaddr parameter in pjsip.conf must reflect the current public IP for NAT traversal to work correctly. If you’re running dual WAN links, you need either a script that dynamically updates externaddr when the active path changes, or a session border controller at the network edge that handles NAT and media anchoring independently of which ISP is currently active. For sites where your network cabling infrastructure already supports redundant uplinks to the core switching layer, extending that physical redundancy through the WAN is the natural completion of the path diversity design. QoS marking rounds out the configuration: SIP signaling at CS3 (DSCP 24) and RTP media at EF (DSCP 46) on all trunk-facing interfaces, applied at the OS level using iptables rules matching destination port 5060 for SIP and ports 10000 through 20000 for RTP.
Where the Configuration Alone Falls Short
Everything above is configuration-level work: dialplan logic, PJSIP parameters, DNS settings, QoS rules. Each piece is necessary and well-documented across Asterisk community resources. But the persistent gap in SIP trunk failover for Philippine enterprise deployments isn’t technical knowledge or configuration syntax. It’s operational testing, or rather, the near-universal absence of it after initial deployment.
Configuring two trunks and writing a failover dialplan takes an afternoon. Verifying that the failover actually works under realistic failure conditions requires disciplined, scheduled testing that most IT teams abandon after go-live. Does the qualify_frequency detection actually mark the trunk as Unreachable within the expected 33-second window (one 30-second interval plus one 3-second timeout)? Does the dialplan correctly read the contact status and skip to Trunk B? Does the NAT traversal survive an ISP failover when externaddr changes mid-session? Does the codec negotiation on the backup trunk match the primary’s G.711 configuration, or does the backup provider force G.729 encoding that your Cisco or Fanvil endpoints can decode but your analog gateway can’t? These questions only have answers when someone simulates failures during a controlled maintenance window.
Commercial tools exist for more complete Asterisk high availability. Telium’s HAAst product, discussed extensively on Server Fault, provides PBX-level failover with sophisticated health detection and state replication between paired Asterisk servers. HAAst can preserve active calls during server failover, which goes well beyond trunk-level redundancy into full architectural resilience. But for organizations where the PBX is a single on-premise appliance, trunk failover as described here is the more immediate and practical investment, and the one most likely to prevent the specific outage scenario that Philippine enterprises actually encounter: a provider trunk goes silent during a Metro Manila fiber cut or a Visayas typhoon, and the system needs to reroute 150 active call attempts to an alternate path within seconds.
The uncomfortable reality is that configuration correctness and operational readiness are two different conditions that feel identical until the moment they diverge. An Asterisk dialplan can be syntactically perfect and logically sound, and the failover can still break in production because of a provider behavior you didn’t test, a NAT edge case you didn’t simulate, or a QoS marking that your ISP’s network equipment ignores despite your local iptables rules applying it faithfully. The configuration gets you to a defensible starting position. Quarterly failover drills, where someone actually disables the primary trunk registration and watches what happens to live call attempts across a 15-minute window, are what separate a failover that exists in the config files from one that works when a typhoon knocks out your primary carrier’s central office in Quezon City.



