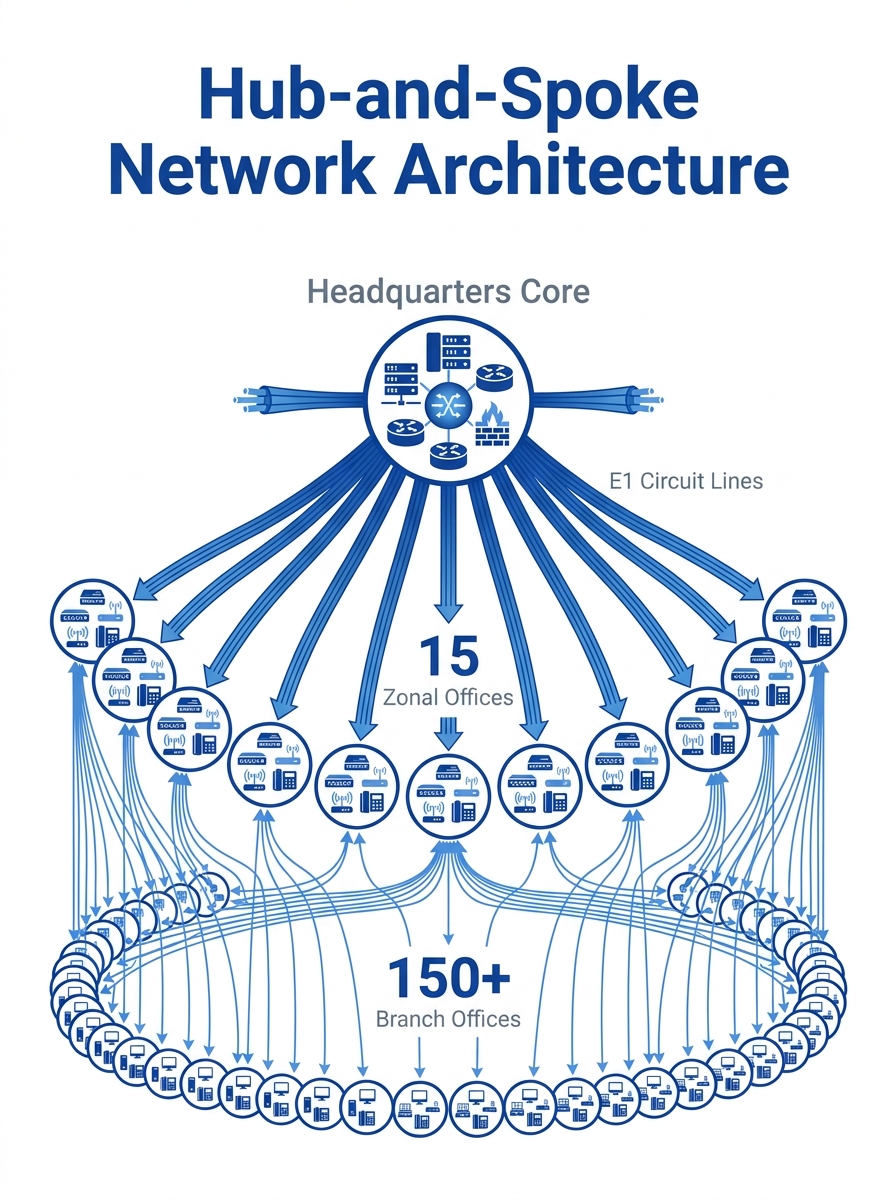
The network diagram in the SANOG25 distributed IP-PBX case study looks like a bicycle wheel drawn by someone with too many spokes. One headquarters sits at the hub. Fifteen zonal offices occupy the inner ring. And beyond those, scattered across the outer rim, 150-plus branch locations each run their own legacy PABX boxes connected to the zones via dedicated E1 circuits. Every inter-office call between branches had to traverse the zone and often route through headquarters, burning circuit capacity on a path that existed purely because the wiring said so, not because the call needed to travel that far.
When the organization decided to collapse this topology onto IP, the migration became one of the better-documented examples of what multi-site VoIP integration really looks like at scale: the architectural tradeoffs, the bandwidth surprises, and the operational gaps that no vendor slideshow prepares you for. This dissection follows the project from legacy wiring through architecture selection, bandwidth planning, failover failures, and the topology that survived.
E1 Circuits, PABX Boxes, and the Cost of Keeping the Wheel Spinning
The pre-migration infrastructure had a straightforward cost problem: E1 circuits are billed per circuit, not per minute. Each of the 15 zonal connections to headquarters required its own dedicated E1 link, and the branches within each zone needed their own circuits to the zonal office. That’s well over 150 individual circuit rentals. The voice traffic on most of those circuits was thin — a few concurrent calls during peak hours, near-zero at night — but the monthly bill stayed the same regardless of usage.
Branch locations ran standalone PABX systems with limited features: basic call transfer, rudimentary voicemail on some, and no integration with email or CRM. If an employee at Branch 47 needed to reach Branch 112, the call routed from Branch 47’s PABX to Zone 3’s gateway, across to headquarters, back out to Zone 9, and down to Branch 112. Four hops for a phone call. Latency accumulated at every hop, and call quality degraded along the way. Inter-office call routing was dictated by physical wiring, not by any intelligent path selection.
The organization had centralized internet connectivity at headquarters, which meant branch employees either had no internet access or used separate consumer-grade connections for data. Voice and data lived on entirely separate networks, doubling the infrastructure maintenance burden.
For Philippine organizations with similarly distributed footprints — think BPO companies with satellite offices across Metro Manila, Cebu, and Davao, or government agencies with regional field offices — this architecture is familiar. Many DICT-connected government offices still operate with legacy PBX infrastructure, and the pain points are identical: rigid routing, high per-circuit costs, and zero flexibility. If you’re evaluating a network-first approach for government VoIP projects, this case offers a useful preview of what breaks first and why.
Centralized Registration vs. Distributed Call Processing
The first major architectural decision was whether to run a centralized or distributed PBX model. This choice shapes everything else in a distributed PBX architecture: bandwidth requirements, failover behavior, feature parity across sites, and management complexity.
In a centralized model, all IP phones at every branch register to a single call processing cluster — typically at headquarters or in a data center. Cisco’s Branch Design Zone documentation describes this approach plainly: you connect IP phones to the branch LAN, and the phones register to the CallManager cluster over the WAN. Simple to deploy. Simple to manage. And absolutely dependent on WAN uptime.
A distributed model places call processing at each site — or at least at each zone. If the WAN goes down, phones at that location keep working because the PBX is local. Inter-site communication breaks, but internal calls within the branch continue. As one analysis from TeleDynamics explains, a distributed call processing architecture has redundancy built in by nature: WAN failure doesn’t mean phone failure.
The SANOG25 organization chose a hybrid. They deployed IP-PBX nodes at each of the 15 zonal offices, with branches within each zone registering to their zone’s IP-PBX over the WAN. Headquarters ran the primary cluster that handled inter-zone routing and PSTN breakout. This gave them distributed redundancy at the zone level without requiring 150 individual PBX installations.
The choice between centralized and distributed call processing isn’t a features debate. It’s a bet on how much you trust your WAN links.
For any Philippine enterprise considering branch office IP telephony, the same question applies. If your branches are connected via PLDT or Globe MPLS circuits with strong SLAs, centralized registration is workable. If some of your branches run on DSL or fixed wireless — common in provincial locations — distributed processing protects you against the link quality you can’t control. Understanding how SIP signaling behaves across these links matters here, because registration keepalives and INVITE transactions are the first things to fail when WAN quality degrades.
Bandwidth Estimation vs. Bandwidth Reality
The migration plan included a bandwidth assessment. The engineering team calculated concurrent call capacity per site, selected the G.729 codec (roughly 30 Kbps per call including overhead), and determined that existing internet connectivity at each zone could handle projected voice traffic. The math checked out.
Then the phones went live, and the math stopped mattering.
The problem wasn’t raw bandwidth. It was contention. The organization’s centralized internet architecture meant that once branches moved to IP telephony, voice packets shared pipe space with web traffic, file transfers, email, and — at certain sites — video streaming. Without strict traffic prioritization, a large file upload at Branch 23 could starve voice packets at Branches 24 through 30 if they shared a common uplink to the zonal office.
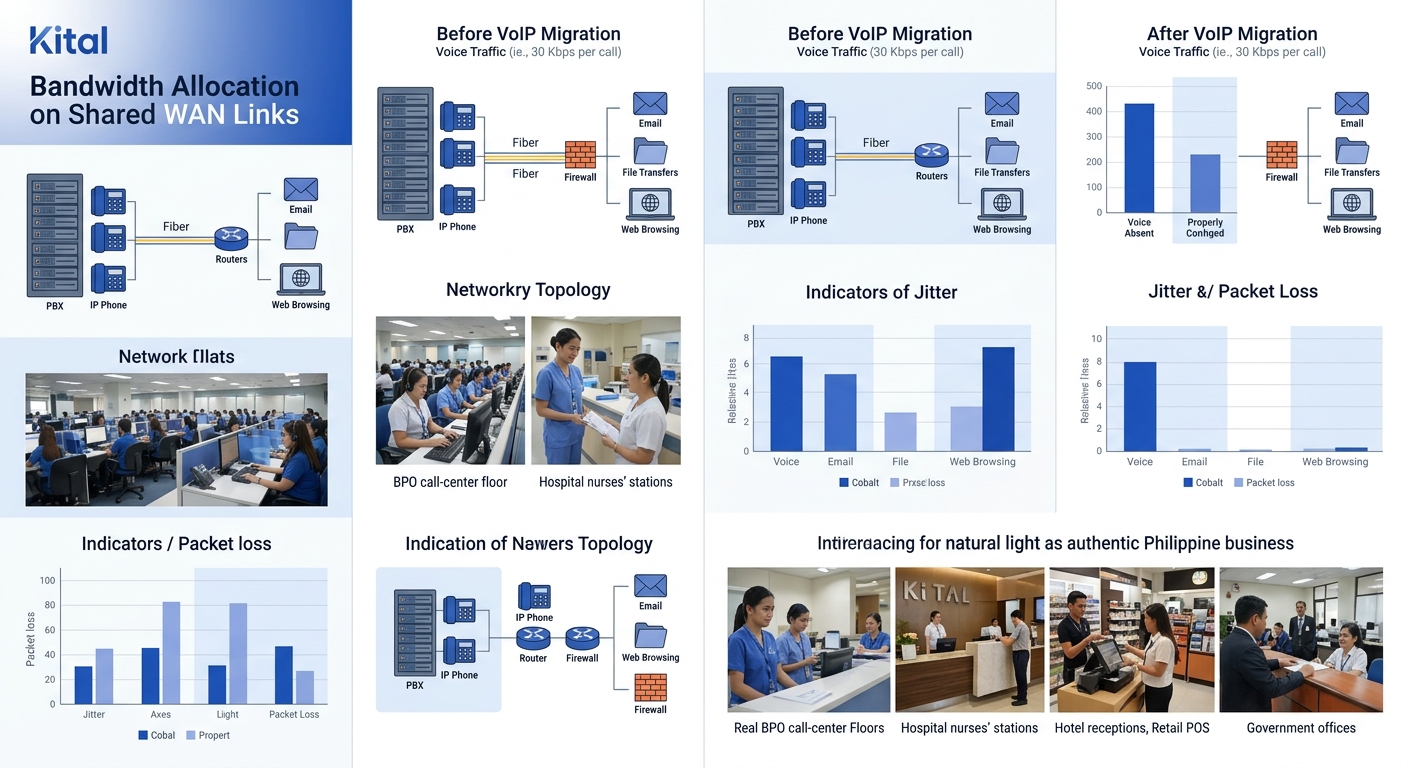
WAN optimization for voice isn’t about adding bandwidth. It’s about protecting bandwidth that’s already allocated. The organization implemented DSCP markings (EF for voice RTP, AF31 for SIP signaling) and configured priority queuing on all WAN-facing router interfaces. But here’s the part that trips up most multi-site deployments: DSCP markings only work if every device in the path honors them. Public internet transit links don’t. ISP-managed connections may or may not. And consumer-grade routers at some branch locations had no QoS capabilities at all.
The engineering team ended up replacing branch routers at 40+ locations to get consistent QoS behavior. That wasn’t in the original project scope or budget. A proper QoS configuration guide would have flagged the need for end-to-end DSCP honoring, but the assumption that existing hardware could handle voice traffic without upgrades is the most common budget surprise in T-1 to IP migrations.
The target thresholds the team worked toward: less than 150 ms one-way delay, under 30 ms jitter, and under 1% packet loss. Getting there required per-site tuning, not a single global configuration template. Each branch had different link characteristics, different traffic patterns, and different peak hours.
According to one VoIP migration planning guide, a true migration to VoIP demands an IT assessment of existing network infrastructure — particularly connectivity and bandwidth that will be shared with the new installation. The SANOG25 case proves the point through hard experience: the assessment has to happen at every individual site, not at the aggregate level.
The Night the Zonal PBX in Region 7 Went Silent
Distributed architecture provides redundancy. But redundancy only works if the failover path actually exists.
Three months into production, the IP-PBX node at one zonal office experienced a hardware failure — power supply burnout during a brownout. (Anyone operating equipment in the Philippines knows that power stability outside Metro Manila ranges from “mostly fine” to “bring your own UPS and pray.”) The 12 branches registered to that zone lost call processing immediately. Internal calls within each branch failed because the phones had registered to the zone’s IP-PBX, not to a local survivor router. Inter-branch and external calls were obviously gone too.
The recovery plan assumed the zonal PBX would be the last thing to fail, not the first. Backup focused on WAN link redundancy — dual ISP connections, PSTN fallback trunks — but the PBX node itself had no failover peer. A single point of failure sitting behind two redundant WAN links.
The fix took 14 hours. The organization shipped a replacement unit from headquarters (fortunately, they had spares), and the local team reconfigured it from a backup. During that window, 12 branches had no phone service. For a Philippine enterprise — particularly one where provincial offices have limited mobile signal — 14 hours of dead phones translates directly into lost revenue and operational chaos.
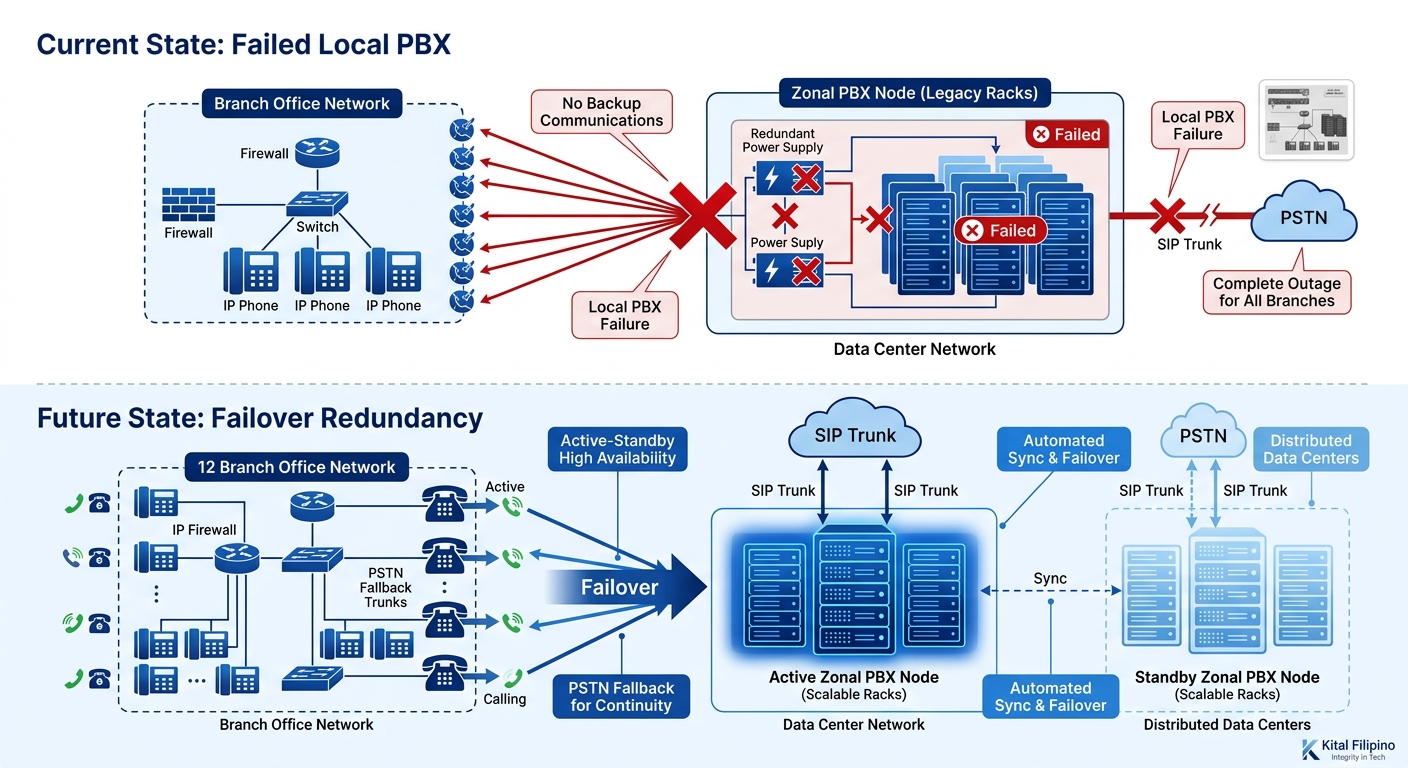
After this incident, the organization deployed standby PBX nodes at each zone and configured Survivable Remote Site Telephony (SRST) on branch routers so that phones could register locally if the zonal PBX became unreachable. This is the approach Cisco ISR platforms (like the 2951 and 3945 series) support natively, providing embedded voice, WAN optimization, and survivability features in a single branch router. The cost of adding SRST licensing and configuration across 150 branches was significant, but the organization considered it non-negotiable after the Region 7 outage.
The lesson is specific and worth stating plainly: in a distributed PBX architecture, you need redundancy at every tier — the WAN link, the PBX node, and the PSTN fallback. Missing any one of those three creates a gap that will eventually be found, usually at the worst possible time. We’ve covered how logging and monitoring can catch these cascading failures before they spread, and the Region 7 incident is a textbook example of what happens when monitoring stops at the network layer and doesn’t extend to PBX health.
The Topology After Convergence
The organization’s post-migration topology bears little resemblance to the original bicycle wheel. Zonal offices now function as regional IP-PBX clusters with hot standby nodes. Branches register to their zone’s cluster over managed WAN links with enforced QoS. Inter-zone calls route over IP between the zonal PBX nodes, with automatic PSTN fallback if the IP path degrades beyond acceptable MOS thresholds. Headquarters still handles centralized management, CDR collection, and PSTN gateway services for zones that don’t have their own trunk connections.
The documented results: inter-office call routing that once required four hops now completes in one or two. Per-site telephony costs dropped by eliminating dedicated E1 circuits. And the organization gained features that legacy PABX systems couldn’t provide — unified voicemail, extension-to-extension dialing across all 150+ branches, and the ability to add new branches by shipping a configured router and phones rather than ordering a new E1 circuit with a six-week lead time.
But the cost savings came with a tradeoff: operational complexity shifted from telecom vendor management (ordering circuits, scheduling technician visits) to in-house network management (monitoring QoS, maintaining PBX firmware, managing SIP trunk configurations). The organization needed to build internal expertise that didn’t exist before the migration. The best practices for VoIP migration planning consistently emphasize training, and this case reinforces why: the infrastructure got simpler, but the skill requirements got harder.
Tip: If you’re planning a multi-site VoIP migration in the Philippines and your branch count exceeds 20 locations, budget for at least 40% of your branches needing router upgrades for proper QoS support. The number is consistently higher than initial assessments predict.
For Philippine businesses evaluating a similar migration path — whether you’re a hospital group connecting provincial clinics, a school system linking campuses, or a government agency unifying field offices under DICT guidelines — the SANOG25 case provides a realistic preview. The architecture works. The cost savings are real. And the gaps in failover planning, bandwidth estimation, and hardware readiness are predictable enough that you can plan for them rather than discover them in production.
If you’re weighing the tradeoffs for your own multi-office deployment, reach out to discuss your requirements with a solutions consultant who can map the architecture to your specific site count and link quality across locations.