Philippine enterprises planning a VoIP pilot program face a three-way design choice that determines whether the pilot produces usable migration data or expensive theater. The single-department test, the multi-branch parallel deployment, and the shadow-run alongside legacy PBX each carry distinct risk profiles, cost structures, and timelines to production confidence.
TL;DR: A phased VoIP migration starts with picking the right pilot structure. Single-department pilots cost the least but produce the narrowest data. Multi-branch parallel pilots stress-test real WAN conditions across Philippine geography. Shadow-run pilots deliver the highest data fidelity but double your infrastructure costs during testing. Match your pilot type to your branch count, budget, and tolerance for disruption.
The instinct most IT teams follow is grabbing the cheapest option, running VoIP on one floor of the Makati office for two weeks, and declaring victory. That instinct is wrong about 60% of the time, according to a 2026 PITON-Global framework analyzing call center migration failures. The root cause: pilots that don’t replicate production conditions generate data that collapses the moment you scale.
VoIP/IPT migration follows a four-stage process covering infrastructure assessment, pilot testing, phased rollout, and optimization. The pilot stage is where Philippine enterprises have the most latitude to prevent problems and the least margin for sloppy design. Here are three ways to structure that stage, what each actually tests, and where each one breaks down.
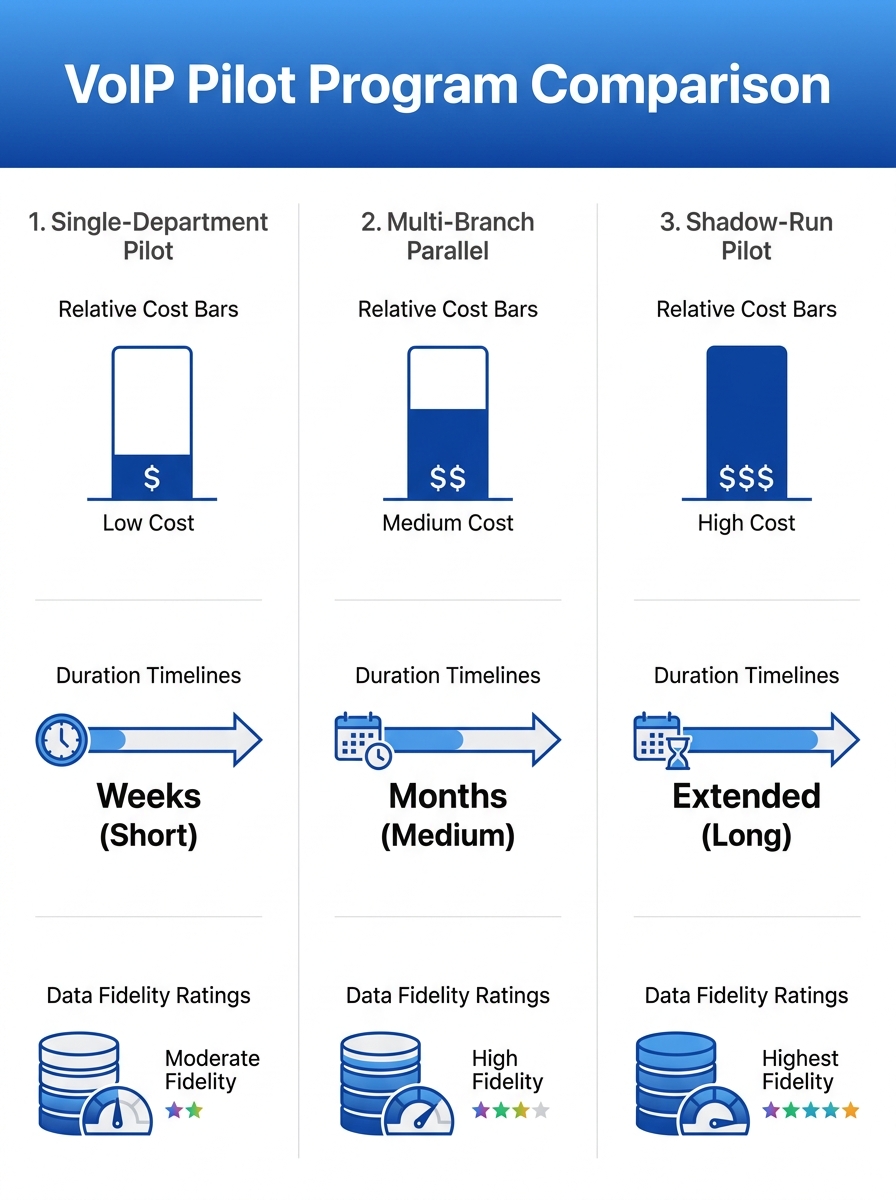
Three Pilot Designs at a Glance
| Attribute | Single-Department | Multi-Branch Parallel | Shadow-Run |
|---|---|---|---|
| Typical duration | 2–4 weeks | 4–8 weeks | 6–12 weeks |
| Relative cost | 1× (baseline) | 2.5–3× | 3–4× |
| WAN condition testing | None | High | Medium-High |
| Call quality validation depth | Limited (LAN only) | Strong (real branch links) | Strongest (side-by-side comparison) |
| Rollback speed | Hours | 1–2 days per branch | Instant (legacy still running) |
| Disruption risk | Low | Moderate | Negligible |
| Data fidelity for go/no-go | Low-Medium | High | Highest |
| Best fit | Budget-constrained, single-site | Multi-branch enterprises, BPOs | Mission-critical voice (banks, hospitals) |
The Single-Department Pilot
Deploy VoIP to one team (typically 15–40 handsets) within a single office, run it for 2 to 4 weeks, and collect call quality metrics before deciding on a broader rollout. ProtectiCloud’s implementation guide recommends you “start with a pilot phase, typically one team or department, to resolve configuration issues and gather feedback” before scaling further.
The appeal is obvious. You’re spending on 15–40 Fanvil or Yeastar endpoints, one SIP trunk, and QoS policy on a single switch stack. Total pilot hardware cost for a mid-size Philippine enterprise typically lands between PHP 120,000 and PHP 280,000, depending on handset tier. Configuration takes 2–3 days. If everything fails, you swap the old analog phones back in before lunch.
But the single-department pilot tests exactly one network condition: LAN. It tells you whether VoIP works on your best-provisioned, lowest-latency, shortest-hop segment. It reveals nothing about what happens when calls traverse your MPLS or SD-WAN links to a Cebu branch running on a 20 Mbps asymmetric fiber connection with 35ms baseline latency. It reveals nothing about how your QoS configuration holds under real inter-site load.
Enterprise telephony testing on a single LAN segment also misses a critical variable: NAT traversal behavior across your WAN edge. If your branches sit behind different firewall vendors (Fortinet in Manila, Cisco ASA in Davao), SIP ALG behavior will differ per site. A single-department pilot can’t catch that.
When the single-department pilot makes sense
You have fewer than 3 locations. Your entire workforce sits on one campus network. Your PBX migration scope is under 100 extensions. You need a proof-of-concept to get executive budget approval for the real pilot.
Where it breaks
The moment you have geographically distributed branches with heterogeneous WAN links, a single-department pilot produces call quality validation data that applies to maybe 20% of your production environment. Scaling decisions based on that 20% is how enterprises end up with dropped calls in Visayas branches three weeks after go-live.
The Multi-Branch Parallel Pilot
Why does the multi-branch approach generate better migration data? Because it forces your enterprise telephony testing onto the actual network paths your production traffic will use. Pick 2 to 3 branches representing different infrastructure profiles: one Metro Manila office on enterprise fiber, one provincial branch on a Converge or PLDT business line, and one site with known bandwidth constraints.
Run the pilot simultaneously across all selected branches for 4 to 8 weeks. SmartChoice’s migration research confirms that a phased migration strategy “minimizes disruption, allows for gradual adoption, and ensures cost management throughout the process”, and the multi-branch parallel approach is the phased VoIP migration model that best balances cost against real-world fidelity for Philippine enterprises with 4 or more sites.
Cost scales accordingly. You’re provisioning SIP trunks per branch, shipping handsets to 2–3 locations, and configuring QoS policy on each site’s router independently. Expect 2.5× to 3× the single-department budget, bringing a typical pilot to PHP 350,000–PHP 750,000 for a mid-size enterprise with 60–120 total pilot endpoints.
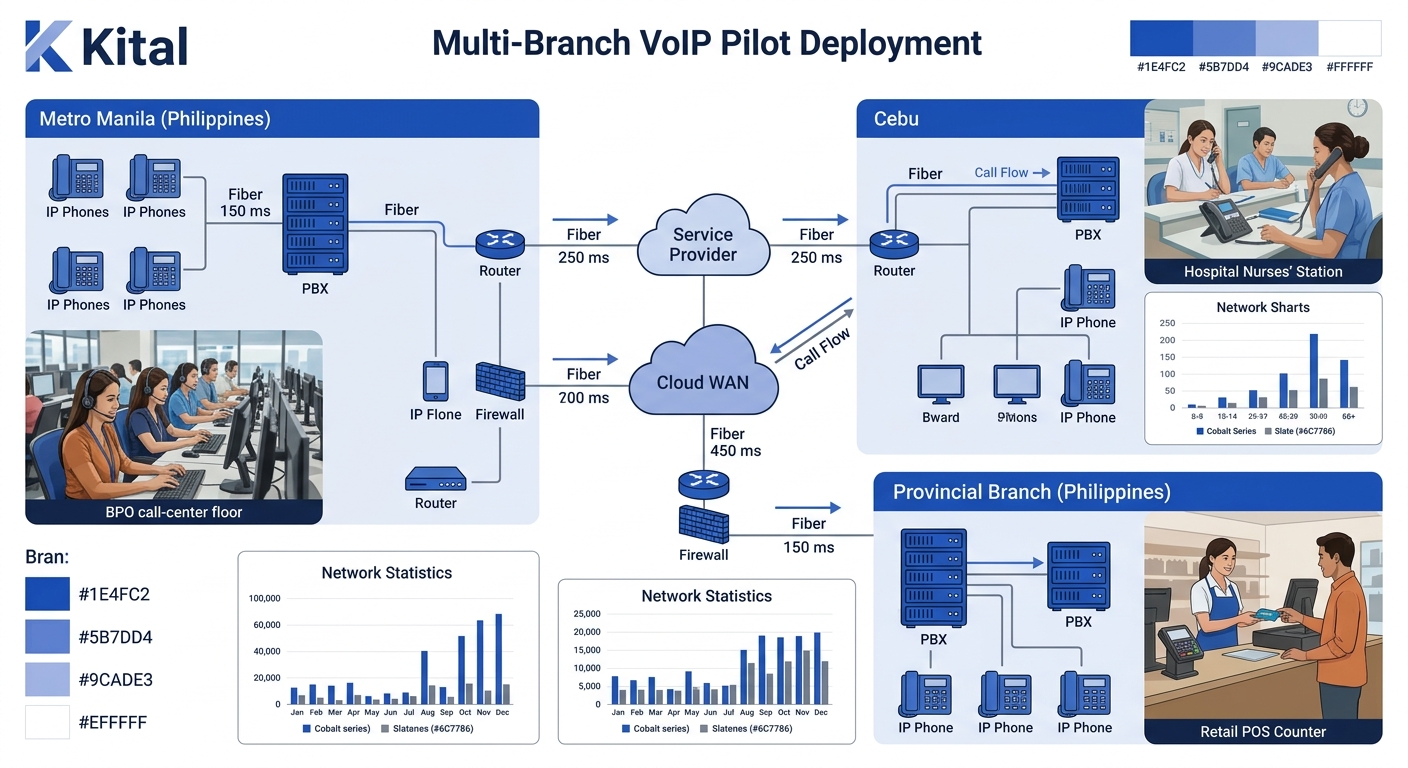
The payoff is data you can trust. You’ll see how jitter and packet loss behave on your Cebu branch’s 25 Mbps link during peak BPO shift hours. You’ll discover whether your codec selection holds up on bandwidth-constrained provincial connections. You’ll identify which branches need QoS policy tuning before production cutover, because the Ookla controlled network testing data from Manila shows measurable differences in voice reliability across Philippine carrier architectures.
The three metrics that matter during multi-branch pilots
Track these per-branch, per-day, for the full pilot duration:
- MOS (Mean Opinion Score) per call leg, targeting 3.8 or above on every inter-branch path
- Jitter at the 95th percentile (not average), targeting under 30ms for G.729 and under 20ms for Opus
- One-way latency per branch pair, targeting under 150ms for domestic Philippine routes
If any branch consistently fails these thresholds during the pilot, you’ve found the weak link before it affects 500 users instead of 30. That’s the entire point of a multi-branch parallel pilot: surfacing branch-specific failures at controllable scale.
Tip: Run your multi-branch pilot across at least one full billing cycle (30 days) so you capture any ISP traffic shaping or bandwidth throttling that kicks in at usage thresholds. Philippine enterprise fiber plans often have soft caps that don’t show up during a 2-week test.
Where it breaks
Coordination overhead. You need IT staff or a systems integrator managing configuration at 2–3 sites simultaneously. Provincial branches without on-site IT may need remote hands or a dispatch, adding PHP 15,000–PHP 40,000 per site visit. And rollback takes 1–2 days per branch rather than hours, because you’re restoring SIP trunk configurations and analog fallback across multiple routers.
The Shadow-Run Pilot
The shadow-run is the gold standard for call quality validation in mission-critical environments. Banks, hospitals, government agencies, and large BPO operations running 500+ concurrent calls use this model because it eliminates the single biggest risk of any enterprise telephony testing program: business disruption during the test itself.
The design is straightforward. Keep your legacy PBX running at full capacity. Deploy VoIP infrastructure in parallel, either duplicating call routing so both systems process the same inbound/outbound traffic, or assigning a subset of extensions to VoIP while maintaining instant fallback to the PBX. VoIPShield’s risk assessment framework emphasizes this approach for organizations where “voice communications are critical” and security assessment needs to cover all equipment in production-equivalent conditions.
Duration runs 6 to 12 weeks. Cost hits 3× to 4× the single-department baseline because you’re maintaining two complete telephony systems simultaneously: PBX trunk charges, VoIP SIP trunk charges, duplicate endpoint licensing, and doubled monitoring overhead. For a 200-seat operation, budget PHP 800,000 to PHP 1.5 million for the pilot phase alone.
The shadow-run eliminates the single biggest risk of any enterprise telephony testing program: business disruption during the test itself.
What you get for that spend is unmatched data fidelity. You’re comparing VoIP call quality against your existing PBX call quality on the same routes, at the same times, with the same callers. MOS scores become directly comparable. Latency measurements have a baseline. And if VoIP quality degrades at any point during the pilot, zero users are affected because every call has a PBX fallback path.
This model also gives your team time to address VoIP security hardening before production cutover. Running parallel systems for 8–12 weeks means your security team can conduct penetration testing, SIP vulnerability scanning, and access control validation on the VoIP stack without touching production voice traffic.
Where it breaks
Cost, obviously. But the subtler failure mode is organizational: shadow-runs that stretch past 12 weeks lose momentum. Teams start treating the VoIP system as optional. The urgency to make a go/no-go decision fades. You end up paying for two telephony systems indefinitely, which defeats the entire purpose of a pilot.
Set a hard cutover-decision date at pilot launch. Week 10 is a reasonable deadline for a 12-week shadow-run. If MOS scores, jitter, latency, and root-cause analysis data all meet your thresholds by week 10, commit to the cutover date. If they don’t, you’ve identified exactly which metrics failed and which branches or routes need remediation before reattempting.

How To Choose Between These Three
The right pilot structure depends on three variables: your branch count, your voice-criticality level, and your pilot budget relative to total migration spend.
Pick the single-department pilot if you operate from 1–2 locations, your total extension count is under 100, and you need board-level proof that VoIP works on your network before releasing full migration budget. Understand that you’re buying a proof-of-concept, not a production readiness assessment. Plan for a second, broader pilot phase after approval.
Pick the multi-branch parallel pilot if you have 4 or more Philippine branch locations with varying ISP quality, your migration scope involves 100–500 extensions, and your pilot budget can absorb PHP 350,000–PHP 750,000 for 4–8 weeks of testing. This is the model that best fits the typical Philippine enterprise doing a phased VoIP migration across Metro Manila, Cebu, and Davao offices.
Pick the shadow-run if voice downtime carries direct revenue or regulatory consequences. Banks processing phone-based fund transfers, hospitals coordinating emergency triage, BPO floors handling 300+ concurrent agent calls. The premium you pay for parallel infrastructure buys you zero-disruption testing and side-by-side quality comparison data that removes guesswork from the cutover decision.
Warning: Whichever pilot type you choose, run it long enough to capture real network variability. A 5-day pilot in any configuration is too short to catch ISP congestion patterns, weekend traffic shifts, or the monthly bandwidth spike when your ERP runs batch syncs. Two weeks is the absolute minimum. Four to eight weeks gives statistically defensible data for a Philippine branch deployment across mixed carrier infrastructure.
Regardless of pilot type, build your evaluation around a three-axis scoring model: coverage realism (how closely the pilot network matches production conditions), rollback speed (how fast you return to legacy if the pilot fails), and cost per validated finding (total pilot spend divided by the number of actionable configuration changes the pilot surfaced). A pilot that costs PHP 200,000 and produces 2 findings gives you PHP 100,000 per insight. A pilot that costs PHP 600,000 and produces 15 findings gives you PHP 40,000 per insight. The more expensive pilot often delivers better return.
The enterprises that treat the pilot as a checkbox get checkbox-quality data. The ones that design the pilot to stress every variable they’ll face in production walk into cutover day with a migration blueprint they’ve already validated under real Philippine network conditions. The difference between those two outcomes is the pilot design decision you’re making right now.