A telecom resilience framework protects enterprise voice and collaboration by stacking four independent failover layers: primary PBX, carrier-level SIP trunk redundancy, out-of-band mass notification, and last-resort personal-device coordination. Philippine BCPs routinely cover data backup and office relocation while treating voice infrastructure as self-healing. Voice infrastructure has dependencies at every level, and each one can fail independently during a typhoon, a cyberattack, or a fiber cut along EDSA.
TL;DR: Business continuity communications fail in the Philippines because enterprises protect data and workspace but ignore layered telecom failover. A four-layer communication stack ensures that losing any one path leaves three others operational. Each layer needs independent power, independent carriers, and documented activation triggers tested before typhoon season.
Why Philippine BCPs Treat Voice as an Afterthought
80% of businesses that suffer a major disruption without a continuity plan fail within 18 months, and the failure point is almost never the one they prepared for. The typical Philippine enterprise BCP dedicates pages to data recovery, alternate work sites, and supply chain rerouting. The telecom section, if it exists, reads something like “call the carrier” or “use mobile phones.”
This gap has a structural cause. Data backup has obvious, measurable recovery time objectives (RTOs). The finance team demands them. Voice infrastructure gets treated as a utility, like electricity, with the assumption that the carrier will restore service and people will figure out communication on their own. But a 2019 USAID-backed initiative through the Philippine Disaster Resilience Foundation identified this exact blind spot, aiming to build a harmonized framework for continuity of operations across different stakeholders because individual enterprise plans kept breaking at the coordination layer.
Only 43% of organizations worldwide maintain a formal crisis management plan. In the Philippine context, where an average of 20 typhoons enter the Philippine Area of Responsibility annually and the National Telecommunications Commission (NTC) requires telecom providers to maintain contingency plans under existing regulations, enterprise-side preparedness lags even further behind. Your carrier has a contingency plan. Your enterprise needs its own, because the carrier’s plan protects their network, not your internal communication flow.
The mechanism that closes this gap is what we call the Four-Layer Communication Failover Stack: a structured model for evaluating and building telecom BCP readiness by ensuring each layer operates on independent infrastructure, independent power, and independent activation triggers.
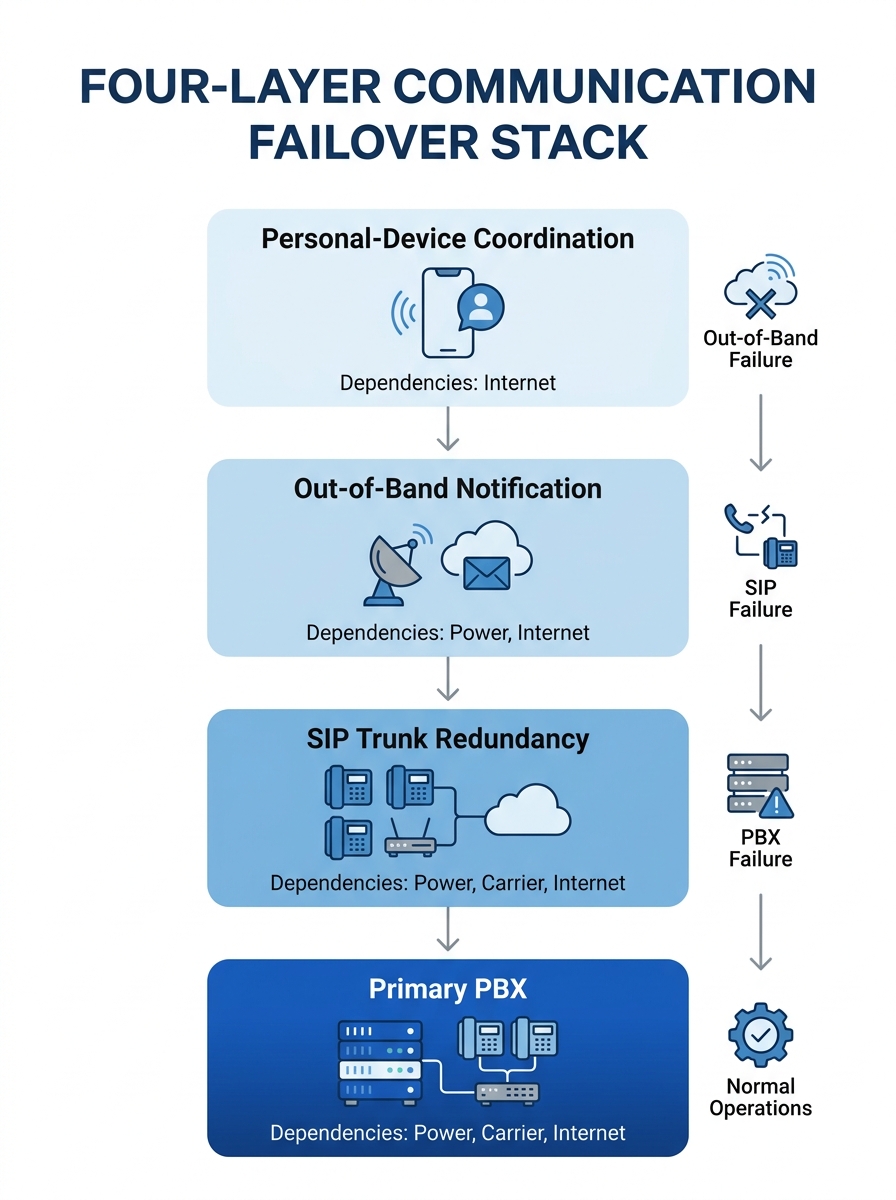
The Primary PBX and Its Hidden Dependencies
The first layer of any failover communication plan is the primary voice platform itself, whether that’s an on-premise IP-PBX running Asterisk or FreePBX, a cloud-hosted UCaaS instance, or a hybrid deployment. This layer handles 100% of daily call traffic, and its failure is what triggers everything else.
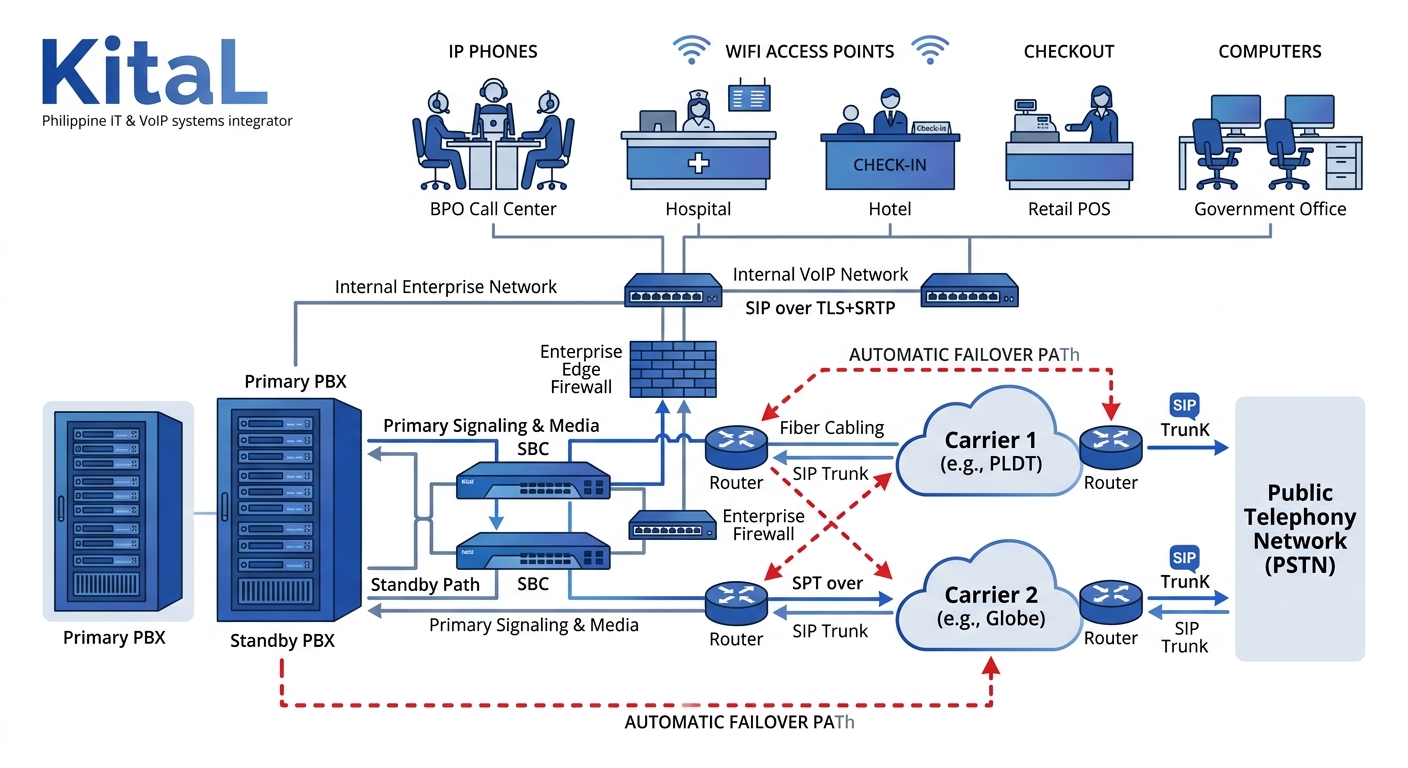
The hidden dependencies are what matter. An on-premise PBX depends on local power (UPS and generator), the LAN switch stack, the SBC or gateway connecting to SIP trunks, and DNS resolution for any cloud-connected features. A cloud PBX depends on your internet uplink, the provider’s data center availability (typically advertised at 99.99% or roughly 52 minutes of downtime per year), and the same LAN infrastructure for desk phones.
Philippine enterprises running on-premise versus cloud PBX systems face different vulnerability profiles. On-premise systems survive internet outages for internal calls but die during extended power failures beyond generator fuel capacity, which in provincial areas can stretch to 72 hours or longer after a major typhoon. Cloud systems survive local power failures if users switch to mobile apps but die during widespread internet disruptions, which PLDT and Globe have both experienced during Typhoon Odette in 2021 when cell tower battery backups drained within 8-12 hours.
Warning: A single-carrier internet connection feeding your cloud PBX is a single point of failure, regardless of the provider’s SLA. A 99.99% SLA means the *provider’s* infrastructure is up. Your last-mile fiber is a separate failure domain.
The first question to answer when documenting this layer: what is the longest duration your primary PBX has been completely unavailable in the past 36 months, and did your BCP detect it or did someone call the IT manager’s personal phone?
SIP Trunk Redundancy Across Carriers
The second layer addresses carrier-level redundancy for voice traffic. A single SIP trunk provider feeding your PBX means that a provider outage, a routing misconfiguration on their side, or a regulatory action takes your voice capability to zero regardless of how healthy your PBX hardware is.
Carrier redundancy requires a minimum of two SIP trunk providers from different underlying networks. In Metro Manila, pairing PLDT with Globe or a smaller provider like Eastern Telecom creates genuine path diversity. In Cebu or Davao, options narrow, but Converge ICT’s provincial fiber expansion adding nearly 1 million new ports strengthens the secondary-carrier picture outside Metro Manila.
The technical mechanism here involves SIP trunk failover configuration at the PBX or SBC level. The PBX monitors the primary trunk’s registration status and SIP OPTIONS responses. When the primary trunk fails to respond within a configured timeout (typically 30-60 seconds), the PBX re-routes outbound calls through the secondary trunk and updates inbound routing via DID number porting or simultaneous ring configurations.
An SBC deployed at the network edge handles this failover more gracefully than a PBX doing it natively, because the SBC can perform health checks against multiple trunk providers simultaneously and make routing decisions in under 5 seconds. For enterprises with 50+ concurrent calls, the SBC approach reduces failover-related call drops by roughly 60-70% compared to PBX-native failover, where re-registration delays cause a gap of 30-90 seconds during which inbound calls go unanswered.
Out-of-Band Notification as an Independent Third Path
Why do the first two layers sometimes fail simultaneously? Because they share dependencies: the same LAN, the same power grid, the same building, sometimes even the same conduit where fiber enters the premises. The third layer exists precisely to bypass all of those shared dependencies.
Out-of-band notification systems operate on infrastructure completely separate from your primary voice and data network. Mass notification platforms like Everbridge, AlertMedia, or locally deployed SMS gateway appliances push alerts via cellular networks, satellite links, or pre-registered personal email addresses. These systems don’t touch your LAN, your PBX, or your SIP trunks.
For Philippine enterprises, this layer typically combines three channels: SMS blasts through a cellular API gateway (costs run P0.35-0.50 per message through local aggregators), email distribution through a non-corporate email service (Gmail or Outlook.com accounts registered specifically for crisis communication), and a pre-configured group on a consumer messaging app like Viber or WhatsApp that key personnel monitor on personal devices. The critical design constraint is that none of these channels should depend on your corporate network or corporate email server being operational.
Maintaining open communication lines with employees, customers, stakeholders, and media during and after a crisis requires pre-drafted message templates stored in at least two locations: the mass notification platform itself and a printed copy held by each member of the incident response team. 90% of companies that recover quickly from a major disruption had a documented plan, and pre-drafted templates are the difference between a 4-minute notification cycle and a 45-minute scramble to compose and approve messaging during an active crisis.
The third layer exists because your first two layers share dependencies you haven’t mapped: the same LAN, the same power grid, the same building entry point for fiber.
Personal Devices and Phone Trees
The fourth and final layer is the one nobody wants to rely on and everyone eventually does: personal mobile phones, pre-printed phone trees, and non-corporate communication channels.
This layer activates when layers one through three have all failed, which in the Philippine context means a Category 5 typhoon has knocked out commercial power for 48+ hours, cell tower batteries have drained, internet service is down across multiple providers, and your office may be physically inaccessible. It happened during Typhoon Yolanda in Tacloban. It happened during Typhoon Odette in Cebu and Surigao. It will happen again.
The mechanism is deliberately low-tech: a printed contact tree where each person is responsible for reaching exactly two other people, using whatever communication method works (text message, voice call, in-person visit, radio). The tree structure means that reaching 256 people requires only 8 relay levels, and the failure of any single node still allows the tree to propagate through alternate paths.
For BPO facilities running 24/7 operations with 1,000+ agents across shifts, this layer includes designated physical rally points, pre-identified local AM/FM radio stations for broadcast-level coordination, and agreements with barangay officials for information relay. It sounds old-fashioned because it is. It also works when everything digital doesn’t.
Integrating this with your broader business continuity and disaster recovery approach means documenting these personal-device procedures alongside your data recovery runbooks and testing them under the same drill schedule.
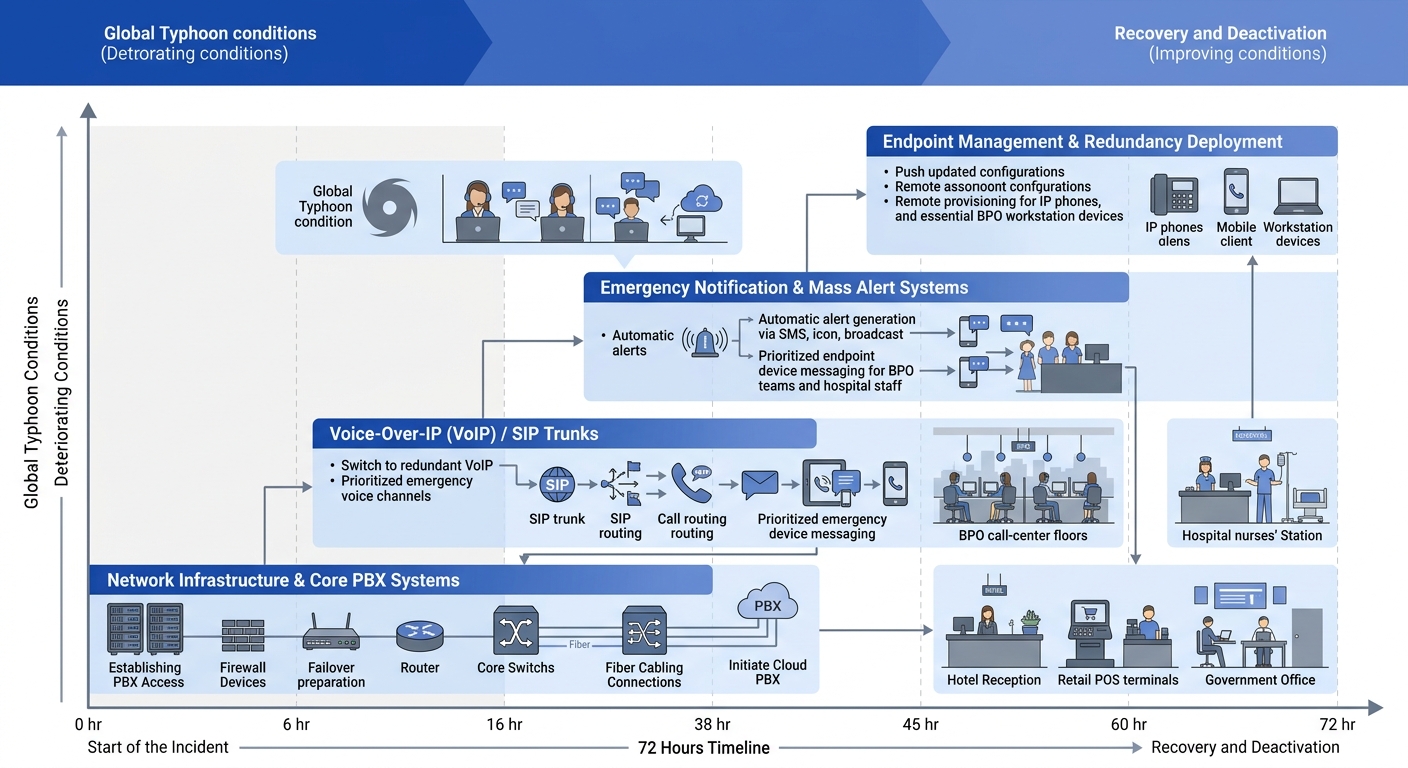
How the Layers Activate During a Real Outage
The four layers don’t all activate at once. They cascade based on severity and duration. Understanding the activation sequence is what separates a documented failover communication plan from a list of phone numbers in a binder.
| Outage Scenario | Duration | Layers Activated | Activation Trigger |
|---|---|---|---|
| Single SIP trunk failure | 0-5 minutes | Layer 2 (auto-failover) | SBC health check failure |
| Building power outage, generator running | 0-4 hours | Layers 1-2 (normal ops on backup power) | UPS transfer detected |
| Carrier-wide internet outage | 2-12 hours | Layers 2-3 | Both SIP trunks unregistered for 10+ min |
| Regional typhoon, multi-day outage | 12-72+ hours | Layers 3-4 | Incident commander declares Level 3 |
| Cyberattack disabling corporate network | Variable | Layers 3-4 immediately | Security team isolates network |
The incident response team designation matters enormously here. 75% of organizations now conduct regular drills, but most drills test layers one and two only: the SIP trunk fails over, the backup generator kicks in, everyone confirms desk phones still work. What Philippine enterprises routinely skip is testing layers three and four, the scenarios where the building is dark and the IT team is coordinating from their homes using personal phones.
Simulated full-stack drills should run annually, ideally in Q2 before the June-November typhoon season. Each drill should measure time-to-first-notification (target: under 5 minutes for layer 3), time-to-full-roster-acknowledgment (target: under 60 minutes for layer 4), and the percentage of personnel successfully reached through each channel. Any channel that reaches fewer than 80% of its assigned contacts needs redesign.
If your existing disaster recovery plan hasn’t been stress-tested against real typhoon conditions, the four-layer stack gives you a structured way to identify which layers will hold and which will collapse under sustained regional infrastructure failure.
Where the Four-Layer Stack Breaks Down
The four-layer model has three known weaknesses that Philippine enterprises should evaluate honestly before adopting it.
The first weakness is cost. Maintaining two SIP trunk providers, a mass notification platform subscription, and printed phone trees with quarterly updates costs money that doesn’t show ROI until a disaster hits. For a 200-seat enterprise, expect P15,000-25,000 monthly for redundant SIP capacity and P8,000-15,000 monthly for a mass notification platform. Budget-constrained organizations can start with layers two and four (redundant trunks and phone trees) and add layer three when budget allows, since those two layers cover the most common failure scenarios.
The second weakness is maintenance decay. Phone trees go stale within 90 days as employees change roles, phone numbers, and reporting structures. Mass notification contact lists drift. SIP trunk failover configurations that worked during the last test break silently after a PBX firmware update. The stack requires a named owner, typically someone in IT operations, with a quarterly review cycle and documented update procedures.
The third weakness is the assumption of personnel availability. All four layers assume that key personnel are alive, uninjured, and able to participate. In a severe typhoon, that assumption fails. The phone tree must have depth, with at least two alternates designated for every critical node. The incident response team needs three tiers of succession documented so that the plan activates even if the primary incident commander is unreachable.
Despite these weaknesses, the four-layer structure works because each layer’s failure mode is independent. A SIP trunk outage doesn’t affect your SMS notification gateway. A building fire doesn’t affect your personal-device phone tree. A cyberattack on your corporate network doesn’t affect printed contact lists. The model breaks when two or more layers share an unidentified common dependency, which is why the quarterly review must explicitly map every dependency for every layer and flag any overlap. Enterprises that maintain this discipline don’t achieve perfect uptime, but they do maintain communication continuity through disruptions that leave unprepared competitors silent for hours or days.



